Setup your AWS S3 integration
Fill in your AWS Account ID
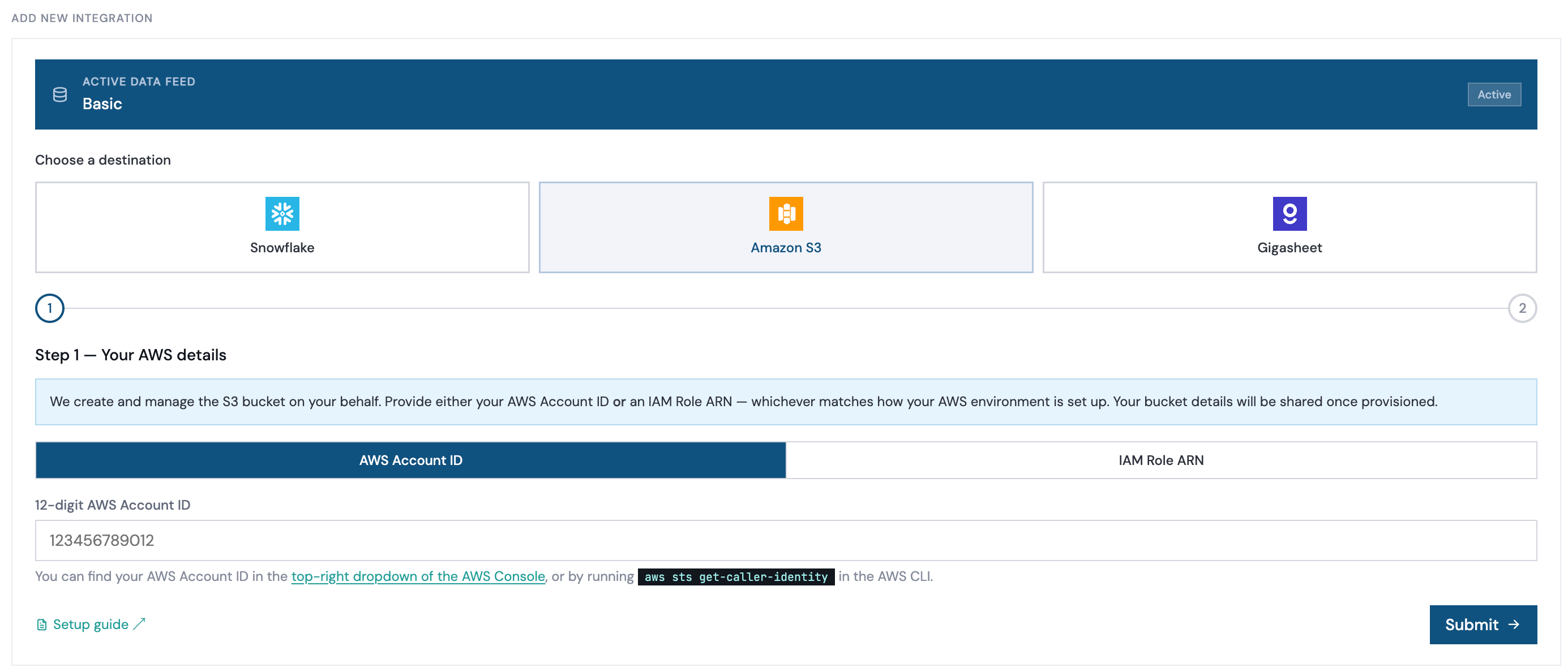
Step 1 — Your AWS details, submit your AWS Account ID.You can find your AWS Account ID in the top-right dropdown of the AWS Console, or by running
aws sts get-caller-identity in the AWS CLI.Wait for bucket configuration
Once your AWS Account ID has been submitted, please allow up to 24 hours as we prepare to provision your S3 buckets. Once provisioned, you will receive an email including your bucket ARN, region, access details, and a step-by-step setup guide.
Bucket structure
Your data lives in date-stamped folders within the S3 bucket. The path structure is:| Path segment | Description |
|---|---|
delivery_date | Date of delivery in YYYYMMDD format (e.g., 20260201) |
dataset_name | The dataset included in your subscription (e.g., per, org, or a pre-joined dataset) |
file_format | One of json, csv, or parquet |
Data is split across multiple files within each delivery folder. This is by design — it enables parallel processing and significantly improves import performance for large datasets.